Data Science Methodenkurs
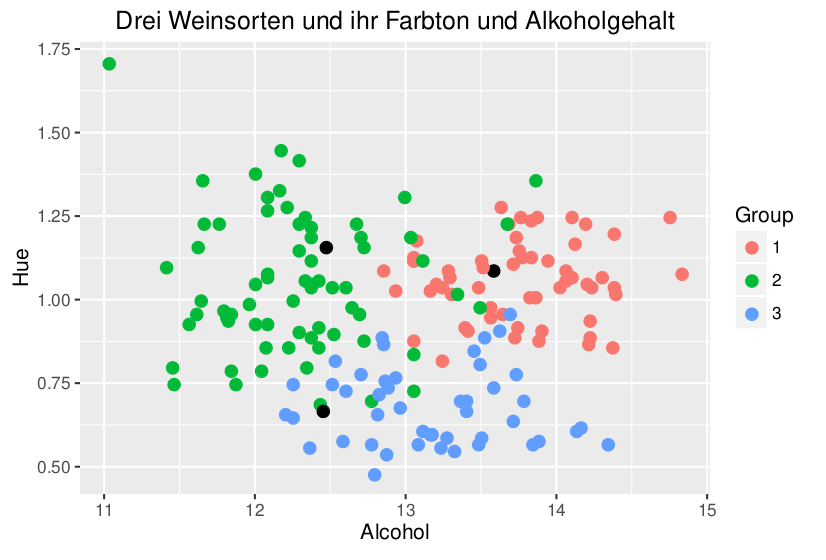
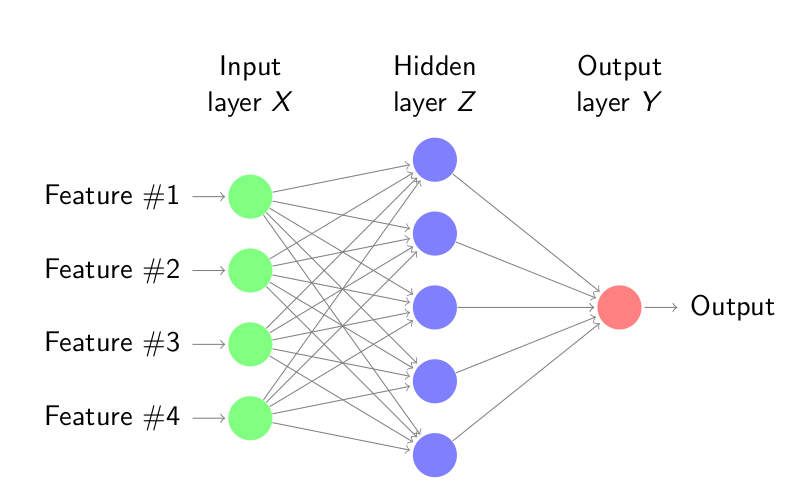
Im Data Science Methodenkurs werden Methoden aus dem Bereich Data Science und Machine Learning, sowie die statistischen Grundlagen, die zum Verständnis dieser Methoden nötig sind, vorgestellt. Der Kurs gibt einen breiten Überblick über das Themengebiet, ohne zu tief in die mathematischen Details einzutauchen. Zwei Case Studies am Ende demonstrieren die praktische Umsetzung der gelernten Konzepte.
In diesem Kurs kommt keine explizite Data Science Software wie z.B. R oder Python zum Einsatz. Alle Themen werden allgemein behandelt. Die beigebrachten Methoden, Beispiele und Aufgaben sind unabhängig von der später verwendeten Software.
Der Kurs behandelt folgende Themen:
Statistische Grundlagen
Einführung in die deskriptive Statistik und statistische Inferenz (z.B. Hypothesen-Tests und deren Interpretation)
Das lineare Regressionsmodell (Aufbau, Anpassung, Annahmen, Goodness of Fit)
Generalisierte Lineare Modelle (z.B. Logit - Modell) und generalisierte additive Modelle (z.B. Modellierung nicht-linearer Effekte mit Splines).
Gütemaße, Modellwahl und Variablenselektion
Wissenswertes: Erläuterung von Problemen und Fallstricken (z.B. Under-/Overfitting, Bias-Varianz-Tradeoff, Kolinearität, Confounder-Variablen, etc.)
Machine Learning Grundlagen
Einführung in Data Science und Machine Learning
Überblick diverser Machine Learning Algorithmen, insbesondere wird hier kurz der Funktionsweise und Intuition der folgenden Algorithmen kurz erläutert:
k-Nearest-Neighbors
Lineare und Quadratische Diskriminanzanalyse
Support Vector Machines
Entscheidungsbäume (Classification and Regression Trees) und Random Forests
Neuronale Netze und Deep Learning
Ensemble-Methoden: Bagging, Boosting, Stacking.
Modellwahl-/ und Validierung: Performance Maße, Trainings- vs. Testfehler und Kreuzvalidierung
Praxistipps: Workflow und bewährte Vorgehensweisen für die Entwicklung von Vorhersagemodellen (Erfahrungen aus Kaggle) und Checkliste für eine ordentliche Datenanalyse.
Präsentation von zwei Data Science Projekten als Fallbeispiele: Analyse von Flugdaten und die Vorhersage von Überleben beim Titanic-Unglück.
Hinweis für Teilnehmer des Machine Learning in R Kurs:
Die Inhalte der beiden Kurse "Data Science Methodenkurs" und "Machine Learning in R"
ähneln sich in kleinen Teilen. Konkret kommen die folgenden Themen in beiden Kursen vor:
- Klassifikationsbäume und Random Forests
- Modellevaluation (Kreuzvalidierung)
- ROC-Kurven
Die Themen sind allerdings in den beiden Kursen anders aufbereitet. Im Methodenkurs werden sie allgemeiner behandelt, und im R-Kurs wird spezifisch auf die Implementierung in R eingegangen.



